了解搜索引擎如何 對網頁進行排名 ——從查詢分類到分配上下文,以及確定哪些信號最重要。作為網站建設、管理者,我們通常關注的問題是“我如何對我的頁面進行排名?”
我們應該問的一個同樣重要的問題是,“搜索引擎如何對頁面進行排名?”
為什麼搜索引擎對網頁進行排名
在我們深入研究搜索引擎如何對網頁進行排名之前,讓我們先停下來想想他們為什麼對它們進行排名。
畢竟,對他們來說,簡單地按字數、新鮮度或各種簡單分類系統中的任何一種來簡單地隨機顯示頁面會更便宜、更容易。他們不這樣做的原因很明顯。你不會使用它。
因此,當我們問關於排名的問題時,我們需要始終牢記的是,我們試圖滿足的用戶不是我們的,他們屬於引擎,而引擎正在將他們藉給我們。
如果我們濫用該用戶,他們可能不會返回引擎,因此引擎無法擁有它,因為他們的廣告收入將會下降。我喜歡把這個場景想像成我們自己網站上的一些資源頁面。
如果我們推荐一種工具或服務,那是基於我們對他們的經驗,我們相信他們也會為我們的訪問者服務。如果我們聽到他們沒有,那麼我們將從我們的網站上刪除它們。這就是引擎正在做的事情。但是怎麼做?
免責聲明
我在Google 或Bing 上沒有竊聽設備。谷歌有一個坐在我的桌子上,另一個我不在的時候隨身攜帶,但由於某種原因,消息拾取不能以另一種方式工作。
我聲明這一點是為了明確以下大綱是基於大約20 年的時間觀察搜索引擎的發展、閱讀專利(或更常見 的是——Bill Slawski對專利的分析),並通過回顧進展來開始多年的每一天-從SERP佈局變化到收購再到 算法更新的行業。
把我所說的當作一個有根據的分類,希望大約90% 是正確的。
如果你想知道為什麼我認為是90%——我從Bing 的Frédéric Dubut那裡了解到 90%在猜測時是一個很好的數字。
這只是一個簡單的5 個步驟- 簡單
對頁面進行排名的完整過程有五個步驟。我不包括負載平衡等技術挑戰,也不是在談論各種信號計算。
我只是在談論每個查詢需要經歷的核心過程,以信息請求的形式開始其生命並以隱藏在廣告海洋下的一組10 個藍色鏈接結束。
了解這個過程,了解它的設計目的是為誰服務,然後您將正確思考如何將您的頁面排名給他們的用戶。
我還覺得有必要注意這些步驟中使用的詞是我的,而不是某種官方名稱。隨意使用它們,但不要期望任何一個引擎使用相同的術語。
第1 步:分類
該過程的第一步是對傳入的查詢進行分類。查詢的分類為引擎提供了執行以下所有步驟所需的信息。在復雜分類發生之前(閱讀:當引擎依賴關鍵字而不是實體時)引擎基本上必須將相同的信號應用於所有查詢。正如我們將在下面進一步探討的那樣,情況不再如此。
在第一階段,引擎會將此類標籤(同樣,不是技術術語,而是一種簡單的思考方式)應用於查詢,例如:
- YMYL
- 當地的
- 看不見
- 成人
- 題
我不知道有多少不同的分類,但引擎需要做的第一步是確定哪些分類適用於任何給定的查詢。
第2 步:上下文
排名過程的第二步是分配上下文。
在可能的情況下,引擎需要考慮他們擁有的關於用戶輸入查詢的任何相關信息。
我們經常看到這個查詢,即使是我們不問的。我們在這裡看到它們:
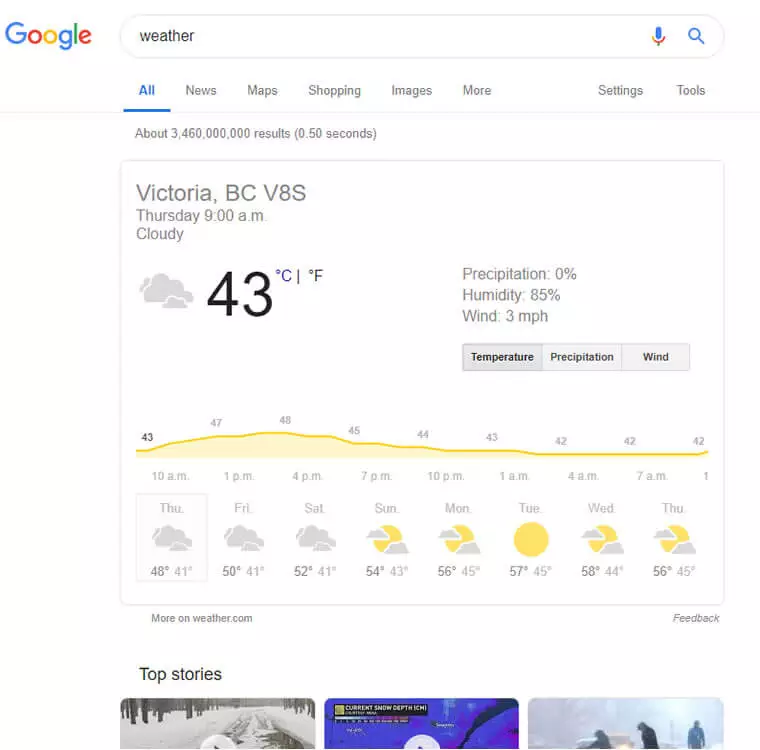
我們在這裡看到它們:

當然,後者是我沒有專門輸入查詢的一個例子。本質上,該過程的第二階段是讓引擎確定哪些環境和歷史因素起作用。
他們知道查詢的類別,在這裡他們應用、確定或提取與被認為與該查詢類別和類型相關的元素相關的數據。
將考慮的環境和歷史信息的一些示例是:
- 地點
- 時間
- 查詢是否為問題
- 用於查詢的設備
- 用於查詢的格式
- 查詢是否與之前的查詢相關
- 他們以前是否看過該查詢
第3 步:權重
在我們開始之前讓我問你,你聽到RankBrain有多噁心?好吧,係好安全帶,因為我們即將再次提出它,但這只是作為第三步的一個例子。
在引擎可以確定哪些頁面應該排名之前,他們首先需要確定哪些信號最重要。對於像[civil war] 這樣的查詢,我們得到如下結果:
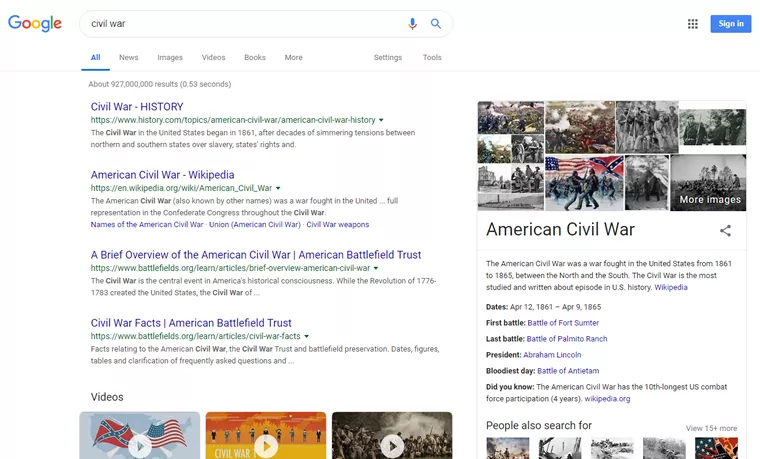
結果很可靠。但是,如果新鮮度發揮了重要作用,會發生什麼?我們最終得到的結果更像:
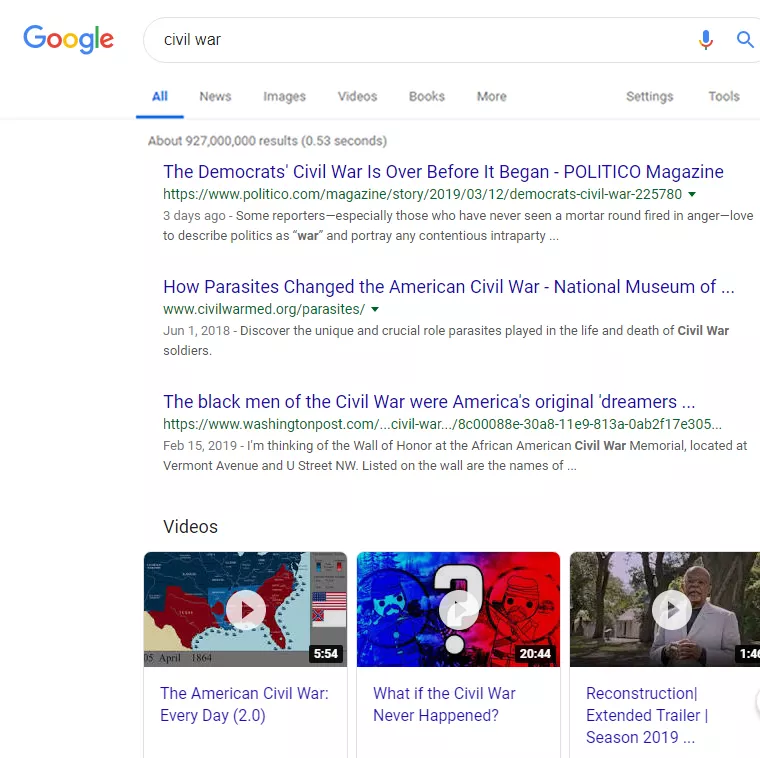
但我們不能排除 新鮮感。如果查詢是[netflix 上的最佳節目],我將不太關心權威,而更關心它的發佈時間。
我幾乎不想要一個2008 年的鏈接緊密的文章,概述了他們服務中訂購的最佳DVD。
因此,有了查詢類型以及提取的上下文元素,引擎現在可以依靠他們對哪些信號適用以及給定組合的權重的理解。
其中一些當然可以由許多有才華的工程師和計算機科學家手動完成,其中一部分將由RankBrain 之類的系統處理,這是(第100 次)一種機器學習算法,旨在調整以前看不見的查詢的信號權重但後來整體引入了谷歌的算法。
鑑於其大約90% 的排名算法依賴於機器學習,因此可以合理地假設Bing 具有類似的系統。
第4 步:佈局
我們都見過。實際上,您可以在上面的內戰示例中看到它。對於不同的查詢,搜索結果頁面佈局會發生變化。
引擎將確定哪些可能的格式適用於查詢意圖、運行查詢的用戶以及可用資源。[內戰] 的SERP 的完整頁面如下所示:
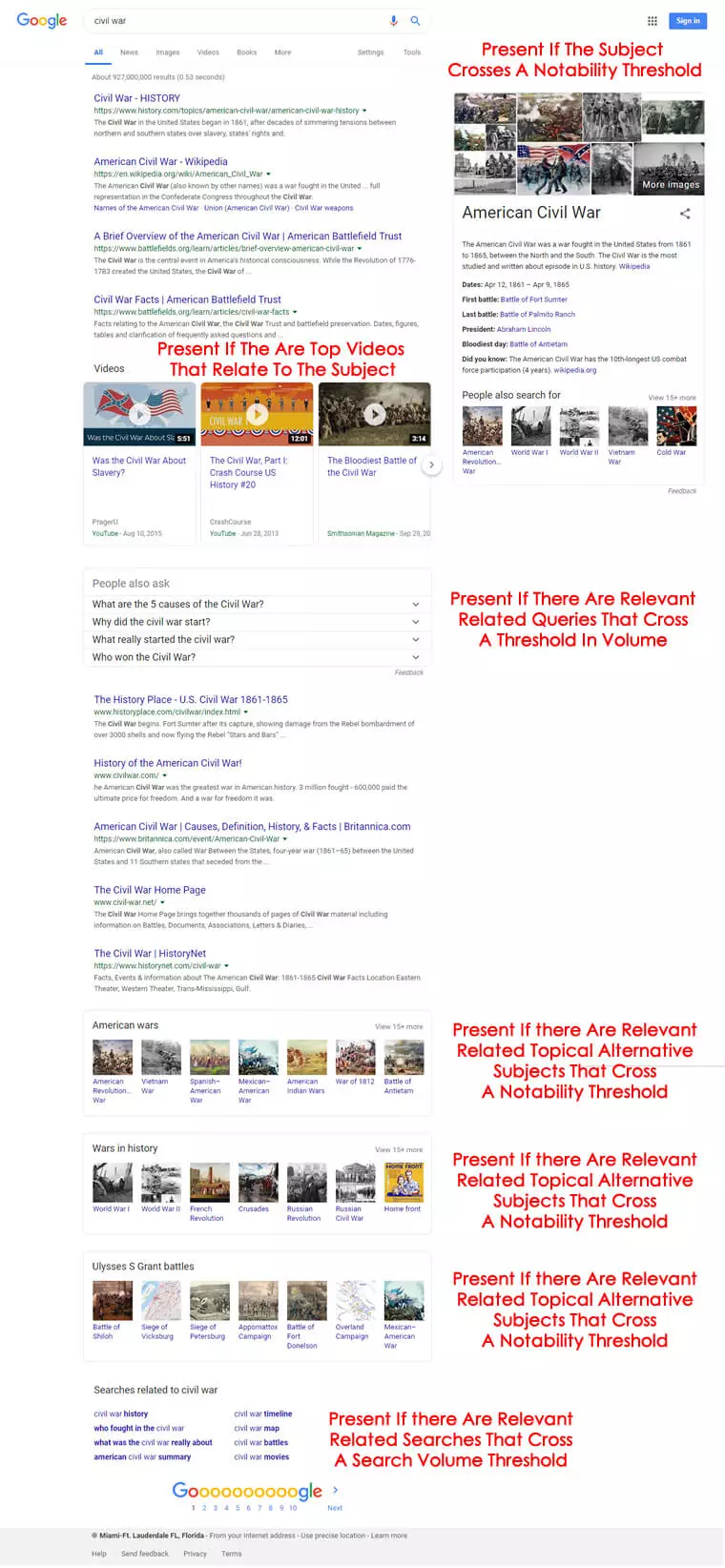
我對用於確定每個元素何時存在的核心因素進行了有根據的猜測。事實是,它是一個移動的目標,依賴於 實體知識、它們如何連接以及它們是如何加權的。這是一個非常複雜的主題,所以我們不會在這裡深入探討。
在本文的上下文中需要理解的重要一點是,任何給定搜索結果頁面的不同元素都需要或多或少地動態確定。
也就是說,當查詢運行並且前三個步驟完成時,引擎將引用數據庫,其中包含要插入頁面的各種可能元素、可能的位置,然後確定哪些將應用於特定查詢。
旁白:我在上面提到,搜索結果頁面或多或少是動態生成的。
雖然這對於不頻繁的查詢是正確的,但對於常見的查詢,引擎更有可能保留一個數據庫,其中包含他們已經計算出的哪些元素以適應可能的用戶意圖,以便不必每次都處理它。
我想它有一個時間限制,之後它會刷新,我懷疑它會在低使用率時刷新完整條目。
但是繼續前進,引擎現在知道查詢的分類、請求信息的上下文、適用於此類查詢的信號權重,以及最有可能滿足查詢的各種可能意圖的佈局。
終於到了排名的時候了。
第5 步:排名
有趣的是,這可能是該過程中最簡單的一步,儘管不像人們想像的那麼單一。
當我們想到有機排名時,我們會想到10 個藍色鏈接。所以讓我們從那裡開始,看看到目前為止的過程:
- 用戶輸入查詢。
- 該引擎會考慮查詢類型並對其進行分類,以了解基於相似或相同的先前查詢交互在高級別應用哪些關鍵標準。
- 引擎會考慮用戶在空間和時間上的位置,以考慮他們可能的意圖。
- 引擎採用查詢分類和用戶特定的信號,並使用它來確定哪些信號應該持有哪些權重。
- 引擎還使用上述數據來確定哪些佈局、格式和附加數據可以滿足或補充用戶的意圖。
有了所有這些,並且已經編寫了算法,引擎只需要簡單地處理數字。
他們將拉入可以考慮進行排名的各種網站,將權重應用於他們的算法,併計算數字以確定網站應該出現在搜索結果中的順序。
當然,他們必須以各種方式對頁面上的每個元素執行此操作。視頻、故事、實體和信息都會發生變化,因此引擎不僅需要訂購藍色鏈接,還需要訂購頁面上的所有其他內容。
簡而言之
網站的排名很容易。把所有東西放在一起做這才是真正的工作。您可能會問,理解這一點如何幫助您進行SEO工作。這就像了解計算機如何工作的核心功能。
我無法製造處理器,但我知道它們的功能,並且我知道哪些特性可以使處理器更快,以及冷卻對它們的影響。
知道這一點後,我就擁有了一台速度更快的機器,而我需要更新和升級的頻率要少得多。搜索引擎優化也是如此。
如果您了解引擎功能的核心,您將了解您在該生態系統中的位置。這將導致在設計策略時考慮到引擎並服務於真正的用戶——他們的用戶。